
10月24日(米国)に行われた Community Live の録画が YouTube で公開されました。
ライブ配信のアーカイブ: https://www.youtube.com/watch?v=KGcCaoI4T6w
AI関連の今回のWebinarでは、セマンティック検索の新機能にまだ触ったことがないという Claris FileMaker 開発者をターゲットに、iSolutions の Cris Ippolite さんが、ゼロからセマンティック検索機能を実装していく様子を、実際にアプリを作成しながら紹介していきます。
今回の内容は、来年3月に米国Austinで開催予定の Claris Engage の Training Day で予定されている、1日フルで実施されるハンズオンセミナーのミニバージョンでもある、とも紹介されていました。米国の Claris Engage 併催のセミナーへの参加を検討している方や興味がある方にも、その雰囲気を知るいい機会かも知れません。

ちなみに、次回の米国の Clairs Engage からは、Training Day は本編のセッションが終わった後のスケジュールで開催されることが予定されているそうで、概念を理解したあとで実際に操作を体験できるようになる、とのことでした。
アンケート結果
本編の前に、いつものようにオンライン参加者へのアンケート結果が紹介されました。
質問1: セマンティック検索の前に、Claris FileMaker に AI 機能を実装したことがあるか?
・20% 「URLから挿入」を使って AI 機能を実装したことがある
・50% 実装の経験なし
質問2: Claris FileMaker 2024 のセマンティック検索について
・50% どこから手をつければいいかわからない
・30% 少し触ったことがある
・5% 実際の開発で使用
・15% FileMaker 2024をまだ未使用
新しいスクリプトステップ・関数の概要
Cris さんのハンズオンセッションの前に、Claris の Ronnie さんから、Claris FileMaker 2024 で導入された AI 関連のスクリプトステップおよび関数の概要が紹介されました。
アカウント管理とログ操作

これらは、実際の生成 AI の API とのやり取りに関する準備の ためのユーティリティ的な機能です。
今回のセッションでは、この Configure AI Account (「AIアカウント設定」)に関して、考え方や使い方についてじっくりと時間をかけて説明がなされていました。
埋込みの生成と操作

これらは、セマンティック検索を実現するために、事前に各データに埋め込み情報を設定するために用いるスクリプトステップや関数です。
埋込み情報をテキストで保持するかオブジェクトで保持するか、オブジェクトの場合に外部格納を使うか使わないか、などについても解説がありました。
この中で、今回使用されるのは、
・Insert Embedding in Found Set
・GetEmbedding
の2つです。
セマンティック検索と類似度

実際に検索を実行するステップと、結果に類似度を表示したり、検索結果をソートするときに使う関数 CosineSimilarity についての説明です。
トークン管理

生成AI APIの利用コストを管理するときに有効な関数です。(今回のハンズオンでは時間切れのため、概要の説明だけでした。)
スキーマ情報

セマンティック検索関連の一連の関数とは直接は関連しませんが、この新しい関数の位置付けもさらっと明かされました。
例えば LLM の機能を活用して、話し言葉でデータベースの内容を答えてくれるようなチャットボットアプリを作成する場合に、問い合わせの質問と一緒にデータベースのテーブル構造をプロンプトに含める必要があります。「URLから挿入」と組み合わせて使うことになりますが、LLM にプロンプトを投げるときに、この関数の戻り値を含めます。
それによって ExecuteSQL に渡す SQL 文を LLM に生成させるという手法です。(これについては長くなるので、機会があったらまた別の記事で)
ファイルとサンプルデータを準備
ここからは Cris さんが、新規作成したファイルに実際にゼロからセマンティック検索の機能を組み込んでいきます。
スターターソリューションから Meetings.fmp12 を選択して、ファイルを新規作成するところから始まります。(日本語環境の場合は「会議」というファイル名になります)
このファイルにインポートするためのサンプルの会議データの CSV ファイルが別途提供されています。
以下の、Claris Community 内のこの Webinar の告知ページからダウンロードが可能です。
↓
CSVデータのダウンロードリンク: https://apple.ent.box.com/s/xs4dzit1vxhtjj3qqwgfq7sh1gpjng11
英語環境の場合は、フィールド名によるマッピングで自動的に正しいフィールドにデータをインポートできますが、日本語の場合は手作業によるフィールドの紐付けが必要になります。
このあと、必要なスクリプトを順番に作成していきますが、作成するスクリプトは3つで、実質的にはそれぞれ1つ(あるいは2つ)のスクリプトステップだけで構成されています。使用するステップの種類は3つだけです。
このあと、スクリプトを作成していきながら、その都度必要となるフィールドを追加していきます。
「AIアカウント設定」
CSV の会議データをインポートしたら、次にセマンティック検索の機能の実装に進みます。(このハンズオンにしたがって進めるには、OpenAI API の有料契約を終えていて、APIキーを取得していることが前提になります。)
まず、スクリプト「Configure AI Account」(日本語のステップ名は「AIアカウント設定」)を作成します。
ここで、アカウント名とは何でしょうか?
これは、OpenAI に対して登録した何かの名前ではなく、このスクリプト内だけで使う通称のことです。セミナーの中では「Sample Account」としています。1種類しかAPIを使わない場合は特に意味は持ちませんが、例えばスクリプトの中で複数の API を使う場合などに、その呼び出し先を使い分けるためにつける名前です。
またここで、OpenAI から取得した API キーを直接スクリプトに埋め込みます。

このステップについて、以下のような Q&A のやり取りがありました。
- このステップを実行するタイミングは?
→ 最初に1回でも、アクセスする前に毎回でもOK - 使用後、オフにする必要はないのか?
→ ない。ほとんどリソースも消費しない - 一度に有効にできるのは、一つだけか?
→ 同時にいくつでも可。複数の API を利用するケースに
「対象レコードに埋め込みを挿入」
次に、「対象レコードに埋め込みを挿入」のスクリプトを作成します。検索ができるようにするために、既存のレコードに一括で埋め込みデータを生成して挿入します。
ここでは、埋め込みデータを生成するモデルを何にするかを決めます。今回は「text-embedding-3-small」が使われていました。
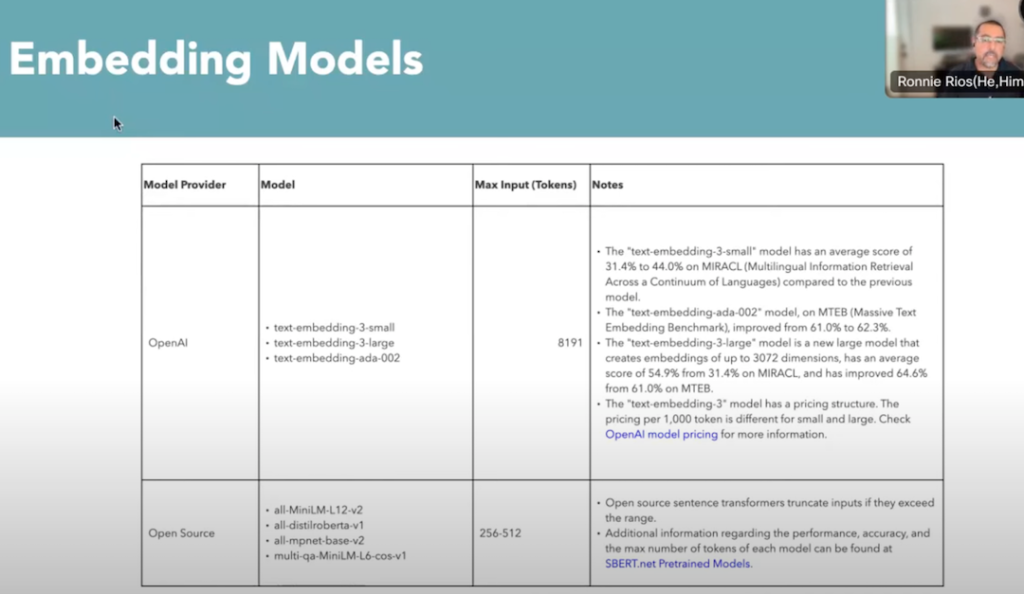
また、埋め込みデータを挿入するためのオブジェクトフィールドを作成します。
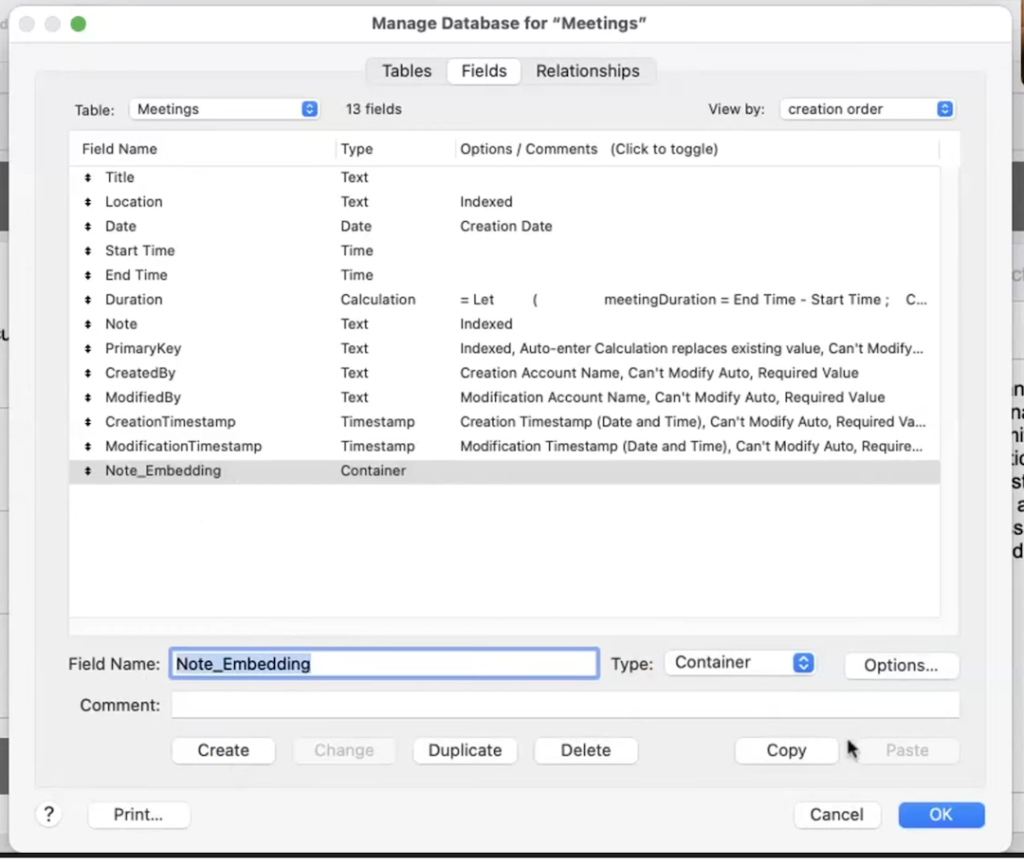
その他、必要なオプションを設定します。

スクリプトが完成しました。
1行目は「AIアカウント設定」スクリプトを呼び出しているだけなので、実質ステップは一つです。

ここで、このステップに関連する補足の説明がありました。
- 対象フィールドをテキストフィールドにするとテキストで、オブジェクトフィールドにするとバイナリで保存される。バイナリにした方がパフォーマンスがいい。
- オブジェクトフィールドを外部格納に指定した場合、パフォーマンスが落ちる。
「セマンティック検索を実行」
3つ目のスクリプトを作成します。これは、実際に検索を行うステップです。
まず、検索する文章をユーザに入力してもらうための、グローバルフィールドを作成します。
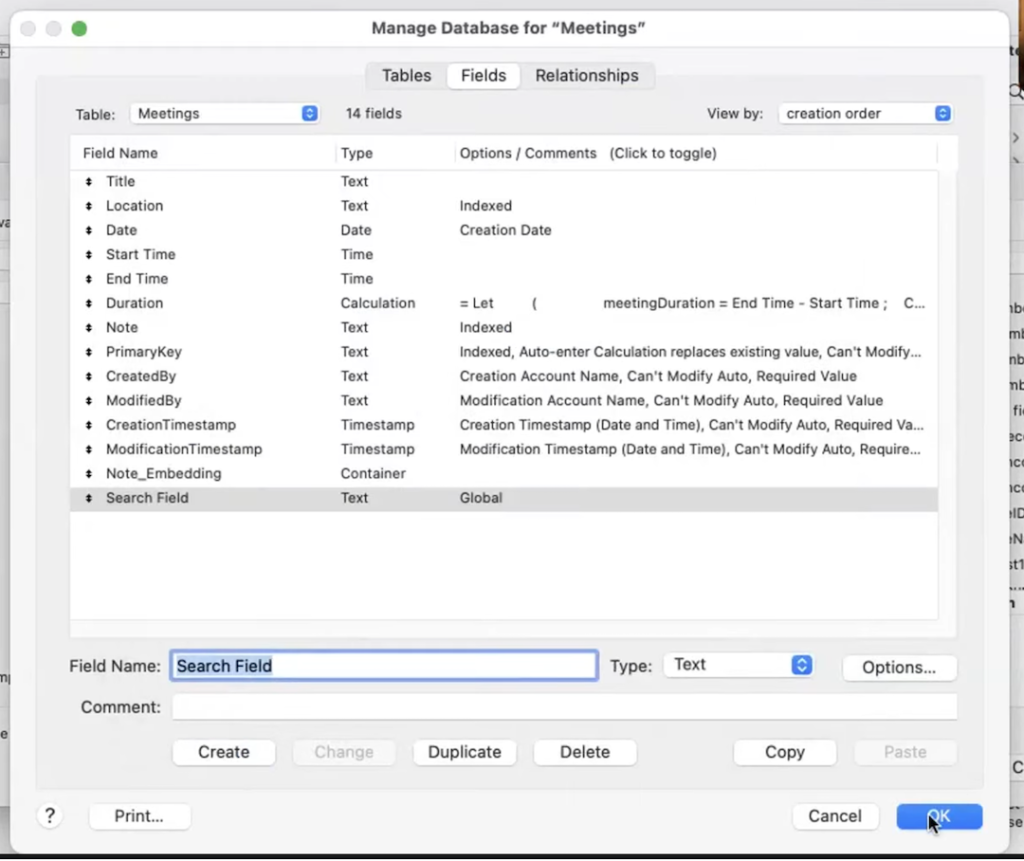
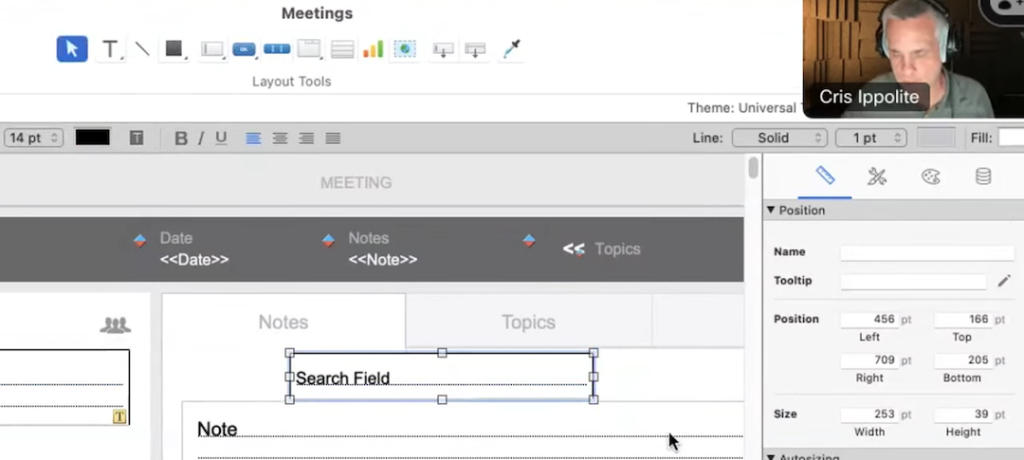
以下が、「セマンティック検索を実行」ステップで設定するオプションになります。

ユーザに画面から文章を入力させる場合は、Query by を Natural language (自然言語)にします。その場合は以下も設定します。

その他のオプションを設定すると以下のようになります。
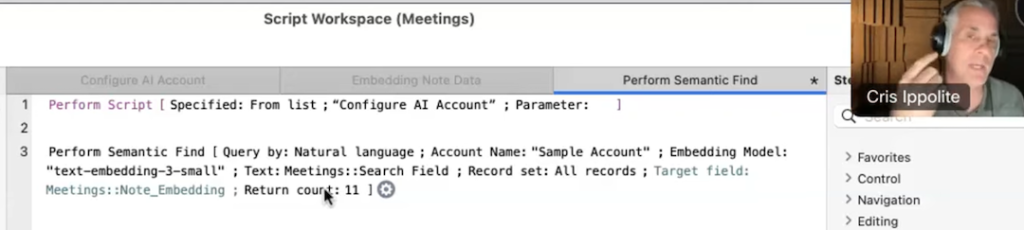
Return Count (返される数)を11としたので、11件が検索され、類似度が高いものから順番にソートされた状態になります。
類似度を可視化したりソートをカスタマイズしたい場合などは、関数CosineSimilarityを使うことになります。
今回は、類似度を画面に表示させるために、CosineSimilarityの計算をレイアウト計算で表示させています。
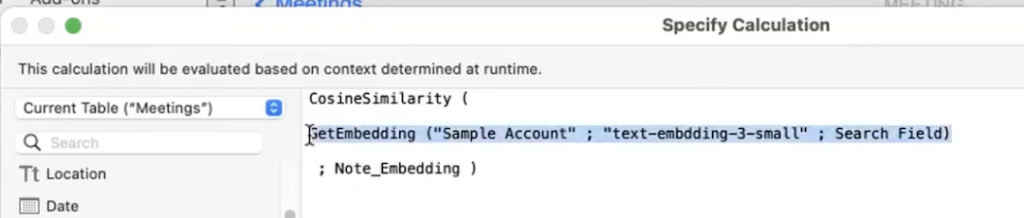
表示するだけであればこれでOKですが、類似度に基づいてソートをしたいということであれば、計算フィールドにするなど、レコードのフィールドに値を保持してソート対象に指定できるようにするなどの検討が必要になると思います。
必要なスクリプトステップは3つだけ
結果的に、このハンズオンセミナーの中で行った、ファイルに対する操作は以下のとおりです。
・スクリプトを3つ作成
・AIアカウント設定
・対象レコードに埋め込み情報を挿入
・セマンティック検索を実行
・Meetingsテーブルにフィールドを2つ作成
・オブジェクトフィールド Note_Embedding
・グローバルのテキストフィールド Search Field
・レイアウト計算を1つ作成
・類似度を画面表示するため(関数GetEmbeddingを使用)
意外と簡単にセマンティック検索を実装できることに驚かれる人も多いのではないでしょうか?
次回はローカルLLMで
今回は OpenAI API を使用する方法が紹介されました。厳密なデータセキュリティが求められる場合は、自社の条件にあったAPIを選択するか ( Microsoft Azure 経由で OpenAI API を使うなどの選択肢も紹介されていました)、ローカル LLM を検討することになります。
次回11月7日(米国時間)には、ローカル LLM を使う方法について SoliantConsulting の Wim Decorte さんから紹介されるそうです。
