Claris FileMaker 2024 で新たに導入された「セマンティック検索」についての理解を深めるため、この新機能に先進的に取り組んでいる Claris パートナーの開発者によるパネルセッションが行われ、YouTube の Claris 公式チャンネルで公開されました。
パネリストとして参加した開発者は、以下の 4 人です
- Ronnie Rios (Claris)
- Ian Jempson (Transforming Digital) Transforming Digital
- Will Miro (Beezwax) Beezwax
- Michael Wallace (Empowered Data Solutions) Empowered Data Solutions
YouTube の Claris 公式チャンネル
https://www.youtube.com/watch?v=m_I0XC-Ta2M
セマンティック検索とは
セマンティック検索とはどういうものか、新しく何ができるようになるのか。これを簡単に示すデモがまず紹介されました。
分かりやすい例として使用されたのが画像検索です。今までは、画像を検索する場合、あらかじめキャプションを人力で付けるなどしなければキーワードで検索することはできませんでした。しかし、FileMaker 2024 の新機能「セマンティック検索」を使えば、それが簡単に実現します。
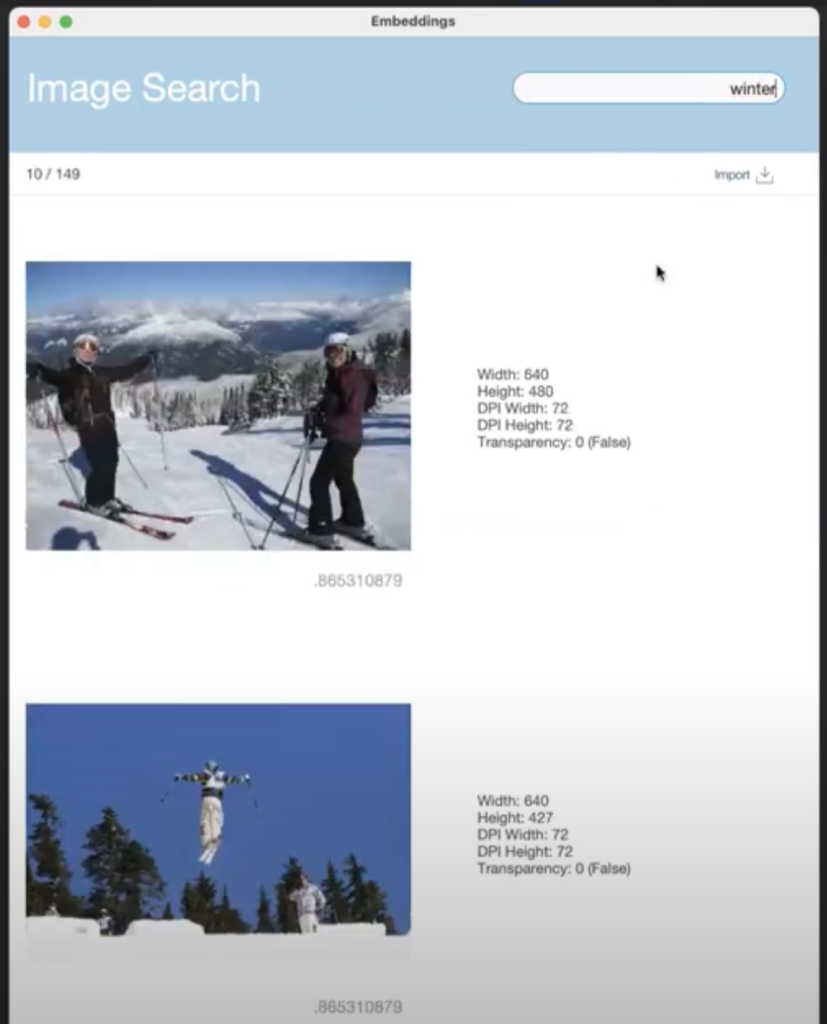
例えば、「winter」で検索すると、冬に関連した画像がキャプションなしでもヒットします。
また、商品カタログのデータベースで、「white sneakers that customers don’t like」(白いスニーカーで、顧客が気に入らなかったもの)という検索条件で、ユーザーレビューの内容も加味した検索結果がヒットする様子が示されました。
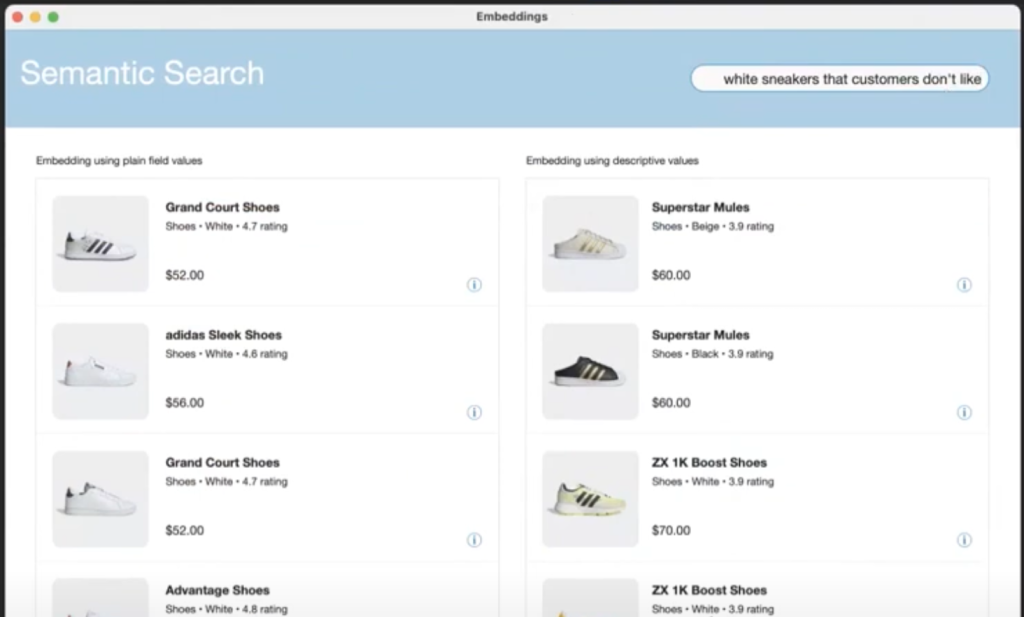
上の図の右側が、ユーザレビューの内容も含んで検索された結果で、レビューの点数が低い商品がリストアップされているのがわかります。
関連して視聴者から、同じ写真を見つけるのに使えるか、という質問もありました。答えとして、まったく同じ写真を見つけるのには別の技術の方が適しているが、内容が似ている写真を見つけるのには有効とのことでした。また、関係がないものを見つける、異常なデータを検出するという用途でも使えそうです。
設定方法と使い方
ここで、FileMaker でセマンティック検索を実装する場合の設定方法と、スクリプトステップ・関数について紹介されました。

これについては、すでに多く出ている紹介記事などと同じ内容になりますので省略します。
弊社の記事 Claris FileMaker 2024 – セマンティック検索のネイティブサポート などを参照ください。
実際の適用例の紹介
実際の適用例がいくつか紹介されました。
以下、印象に残ったものをピックアップして紹介します。
ホテルのレビュー
ホテルのレビューサイトから、レビュー文と評価分類のセット、20,000 レコードをインポートし、このレコードで埋め込みデータを生成して付加します。
「This hotel was terrible, the worst ever」(このホテルはひどかった。最悪)というキーワードで検索すると、10 件が検索されました。同時にインポートした評価分類(rating)を参考で見てみると、検索結果のレコードはすべて 1(最低)となっていて、検索結果と一致しています。
ここでは、OpenAI ではなく自前の Embedding 用サーバーを立てて行っているそうですが、20,000 件でも検索がほぼ瞬時で行われることがわかります。そして分類されたレコードが十分蓄積されたら、その後追加されるレコードについては、生成された埋め込みデータを利用して、スクリプトで内容の類似度を計算し、それに基づいて評価分類を行うことができます。このようにして、評価分類の作業をスクリプトで自動化できたとのことです。
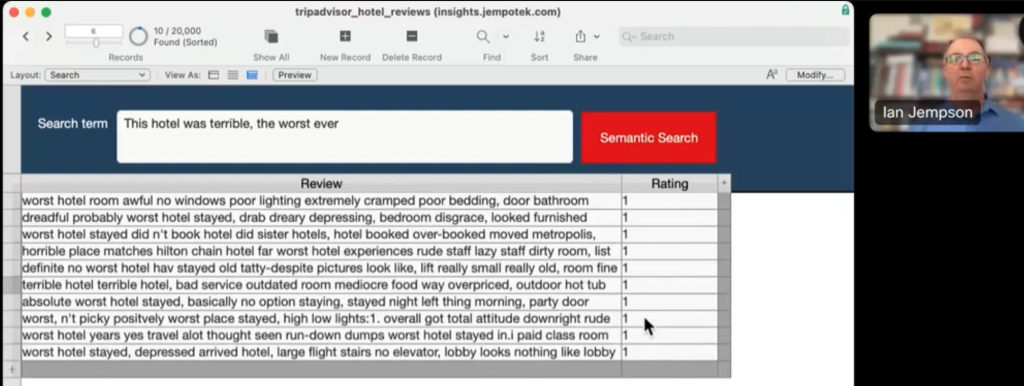
ここでのねらいは、ネットで入手可能なデータに埋め込みデータを付加して、そのデータを辞書のように使い、自社で蓄積するデータに対して評価分類を自動的に行なうという試みです。
データベースに蓄積したテキスト文書によるRAGシステム
Ronnie さんのデモは、技術情報のテキストファイルに対して質問を投げると、その内容に基づいて回答を返してくれるシステムです。世の中で一般に言われる RAG(Retrieval Augmented Generation)システムの一種と言えます。
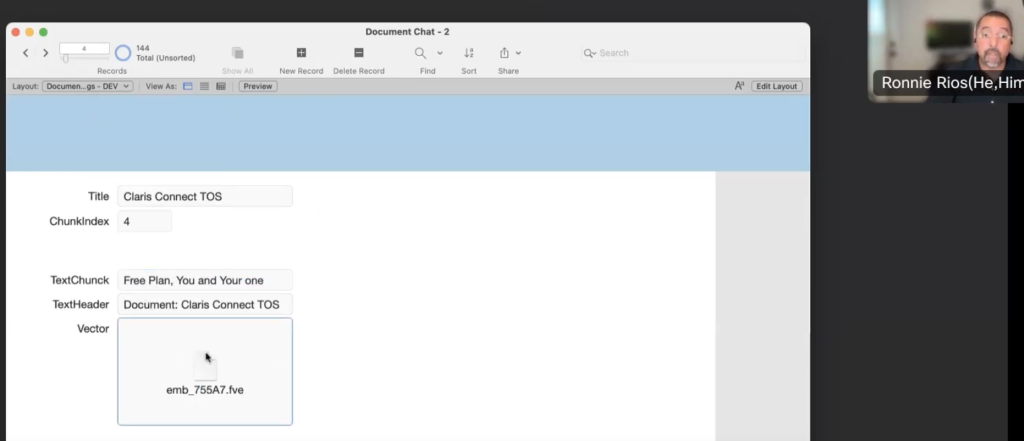
オブジェクトフィールドの中の文書(テキストファイル)を、chunk という一定の文字数ごとのかたまりに分解して別テーブルに保存し、それに対し埋め込みデータを付加してデータベース化しています。この例では、元々 24 個あったテキストファイルを、容量に基づいて 144 個の chunk 部品に分解しています。(画像を見ると、例えば10,000語のテキストは約50個のchunkに分解されています。)
その chunk 側テーブルのレコードに埋め込みデータを付加し、その埋め込みデータに対してセマンティック検索を行っています。
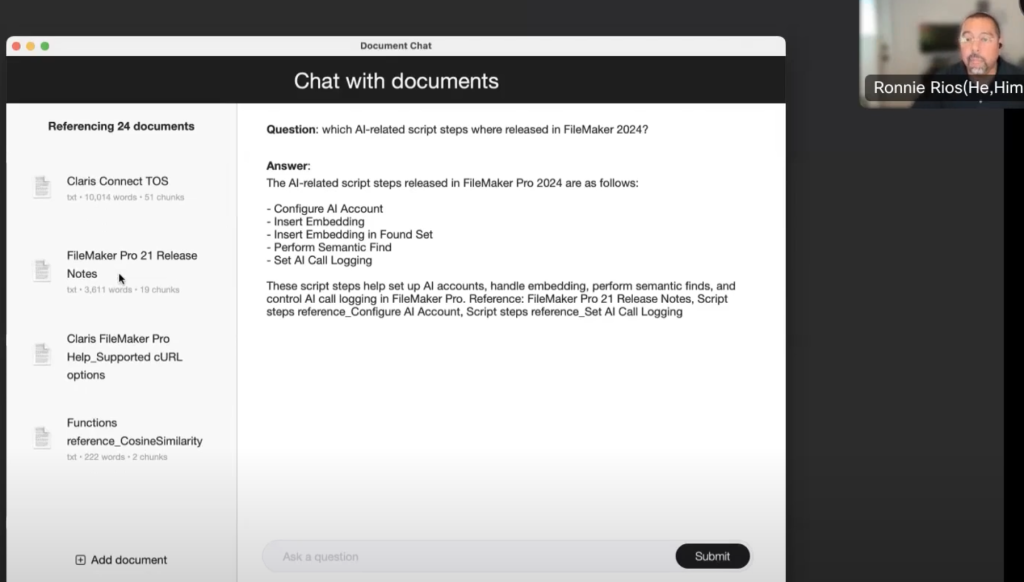
このデモでは説明はなかったと思いましたので補足しますと、埋め込みデータを使って、資料の対象部分の絞り込みを行なって、再度、質問と該当の資料部分を再度生成AIに投げて、質問の回答を自然文として組み立てて、ユーザに返していると思われます。
求職申し込み管理システム
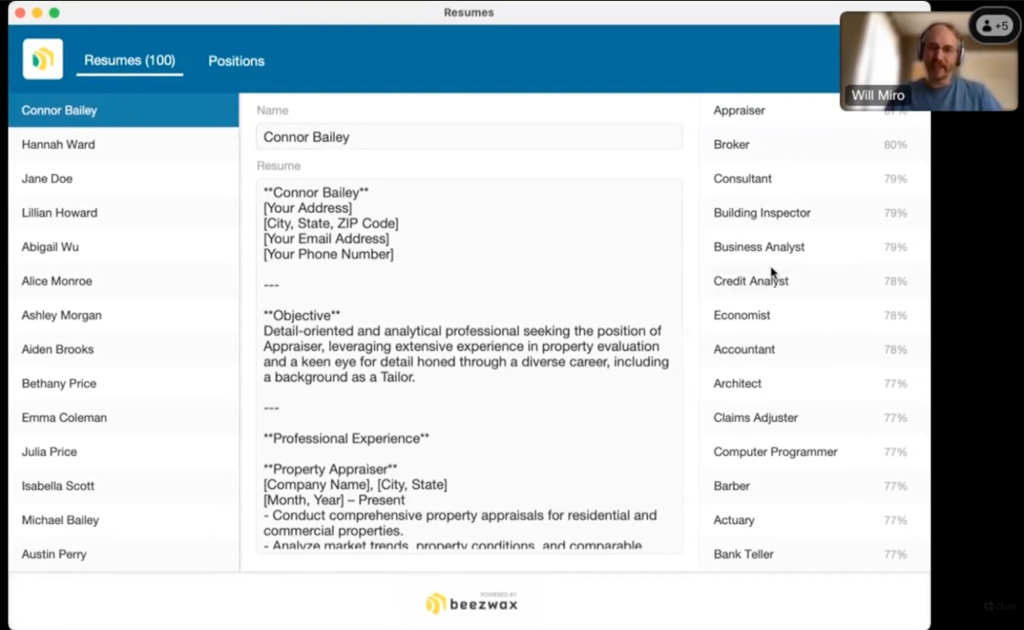
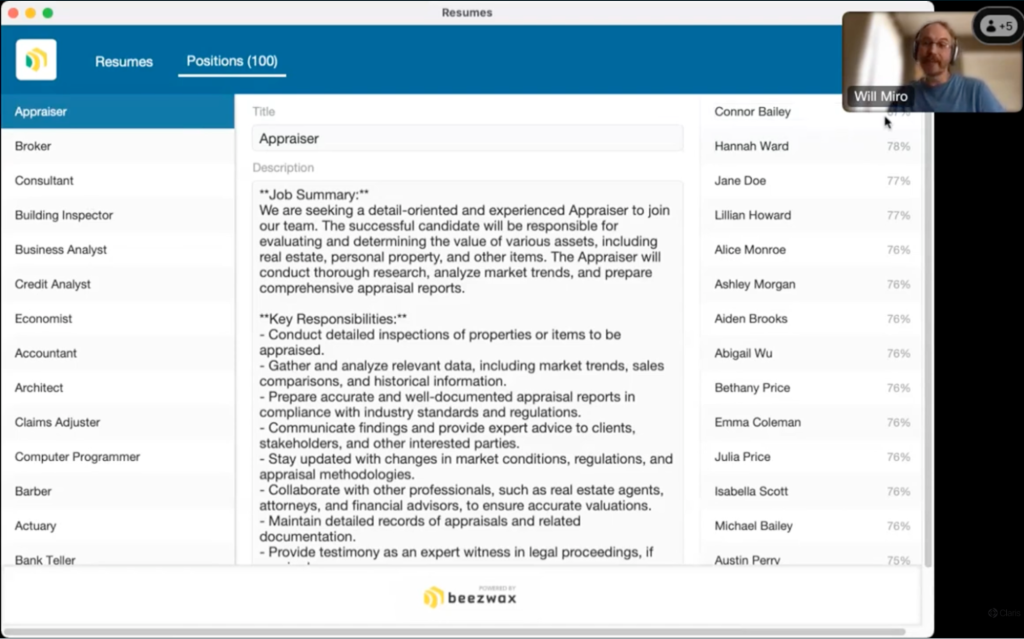
Beezwax の Will さんの求職申し込みを管理するシステムでは、履歴書のデータを見て、どのような職を求めていて、求められる要件を満たしているか、あるいは他によりよいポジションがないか、技能をより活かす組み合わせを探します。
この画面では職位のテーブルと候補者のテーブルを比較して、適正をランキングしています。
候補者側からその人に向いた職種をランク付けして見たり、職種ごとに適任の人をランク付けして見たり、2つのテーブルの両側からそれぞれに関連の深いレコードを見つけるのに利用しています。
「セマンティック検索を実行」スクリプトステップは使わず、すでに取得・保存済みの埋め込み情報を使って、コサイン類似度でソートをかけてリスト表示をしています。
埋め込みデータの容量、保存方法など
デモの紹介の合間に、視聴者から技術的な質問がいくつも寄せられていました。
一つは、埋め込みデータを追加することで、どれくらいデータベースの容量が増えるのか、というものでしたが、実際の計測値を使っての説明がありました。
以下の表は、65 文字のテキストに対して、埋め込みデータを 10 万件のレコードに追加した場合の例です。対象のモデル 3 種類に対してテストしたところ:
- 埋め込みデータをテキストフィールドに保存した場合:2~4GB
- オブジェクトフィールドに保存した場合:1~2.4GB
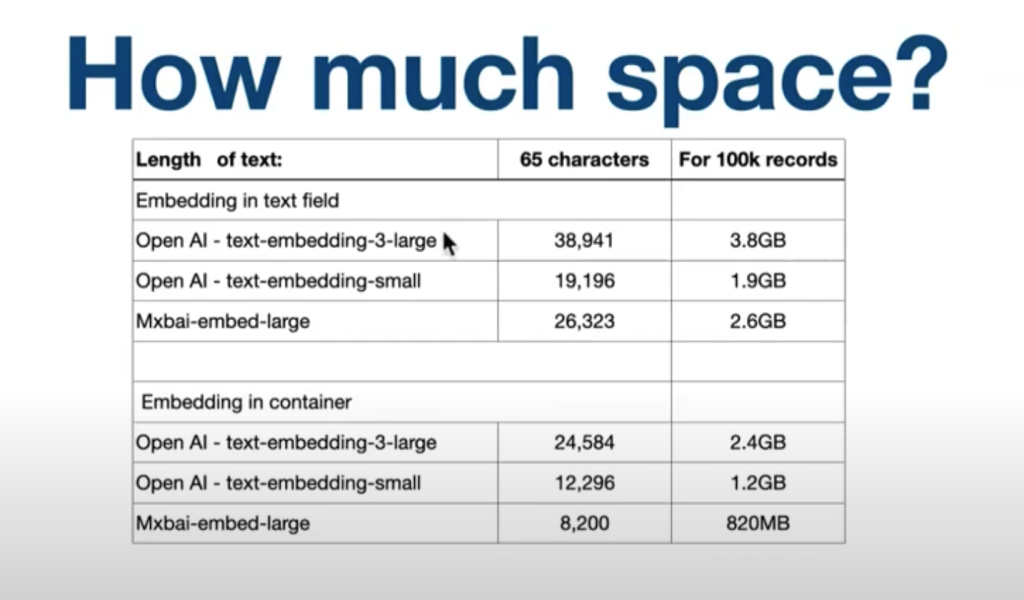
埋め込みデータは、テキストフィールド・オブジェクトフィールドのどちらにも保存可能ですが、オブジェクトフィールドを使用することが効率やパフォーマンスの点から強く推奨されていました。また、もしテキストで保存する場合は、索引をつけないようにします。そうでないと、パフォーマンスが大きく損なわれることになります。
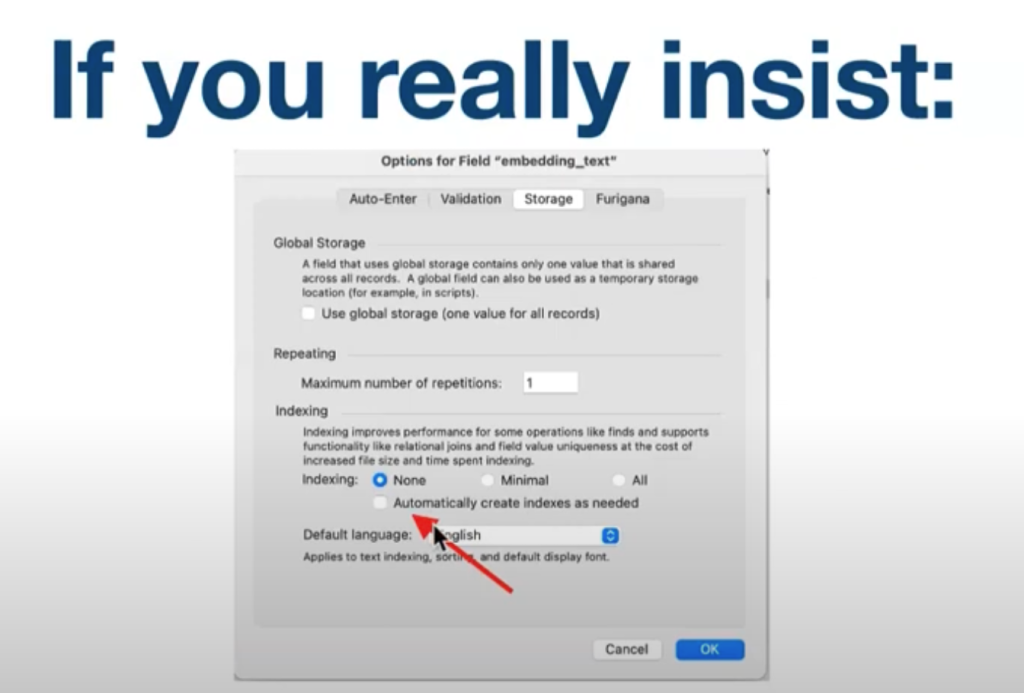
埋め込みデータをオブジェクトフィールドに保存する場合に、外部格納を使ってもいいのか、セキュア格納にすべきかという質問も来ていました。
回答としては、外部格納を設定することは可能だが、速度が遅くなり、セキュア格納ではさらに遅くなります。
データのバックアップ方法をわけて考えるのであれば、埋め込みデータのフィールドを別テーブルに分けたり、さらには別ファイルに分けるという設計も考えられます。
コスト・セキュリティについて
埋め込みデータを今までに蓄積した大量のデータに付与するとなると、API 利用の費用が気になるところかもしれません。
コストに関して言うと、Britanica 30 巻分の 19 セットのデータに埋め込みデータを付加しても $15 だったとのことで、特に気にしなくてもいいレベルとのことでした。
OpenAI APIの場合は、事前に金額を指定してチャージしておくことで、それ以上はチャージされないという設定ができるので、いつの間にか高額な料金が使われていた、というような問題が発生することはありません。
セキュリティに関しては、API 経由の送信データはモデルの学習には使われないという点と、SSL 通信で安全にデータの受け渡しが行われているという点が説明されました。
さらにセキュリティを高めたければ、ローカルに LLM サーバーを立てることも可能であることが紹介されていました。
また、Claris は Apple の子会社としてプライバシーとセキュリティを重視していて、あらゆるレベルの選択肢をユーザーに提供しているので、自身のニーズに合った方法で導入してほしいとのことでした。
最後に
Claris FileMaker 2024の公開に合わせて、生成AI関連の新機能を紹介するライブ配信の第1回の内容を紹介しました。今後も生成AI関連のライブ配信が予定されているようなので、フォローしていきたいと思います。
AI関連の新機能については、なかなか手を出しにくいと感じている開発者の方も多いかもしれません。まずは、このような動画で紹介されている先進事例を見てみることで、今までできなかったどのようなことが実現できるかのイメージを掴むことで、最初の一歩を踏み出してみてはいかがでしょうか?